


 作者:王明辉,国务院发展研究中心产业部研究室主任;任师攀,国务院发展研究中心办公厅(人事局)
作者:王明辉,国务院发展研究中心产业部研究室主任;任师攀,国务院发展研究中心办公厅(人事局)

图片来源:由无界 AI工具生成
ChatGPT是一款由美国OpenAI公司开发的自然语言人机交互应用,拥有接近人类水平的语言理解和生成能力,是迄今为止人工智能领域最成功的产品和历史上用户增长速度最快的应用程序。ChatGPT依赖大模型、大数据、大算力支撑,其出现标志着通用人工智能的起点和强人工智能的拐点,是里程碑式的技术进步,将引发新一轮人工智能革命。
国内人工智能“大模型”已具备一定基础,但与ChatGPT还存在一定差距,其背后面临数据、算力和创新环境等深层次制约。需从战略高度重视ChatGPT引发的新一轮人工智能革命,瞄准大模型、整合大数据、布局大算力,实施包容审慎监管,为新事物发展留足空间,加快抢占未来科技竞争制高点。
ChatGPT具有里程碑意义将引发新一轮人工智能革命
ChatGPT(Chat Generative Pre-trained Transformer,聊天生成型预训练转换模型)是一款由美国OpenAI公司开发的自然语言人机交互应用,拥有接近人类水平的语言理解和生成能力,因其出色的回答问题、创作内容、编写代码等能力,使得人们直观真切地体会到人工智能技术进步带来的巨大变革和效率提升,上线5天用户突破100万,两个月活跃用户突破1亿,是迄今为止人工智能领域最成功的产品和历史上用户增长速度最快的应用程序。
ChatGPT是一个经过长期技术储备、通过大量资源投入、带有一定成功偶然性的人工智能“核爆点”。ChatGPT的发展经历了3个阶段(如下图所示),前期GPT-1(2018年)、GPT-2(2019年)、GPT-3(2020年)等版本已经投入了大量资源(包括购买高性能芯片、雇佣数据标注人员、占用计算资源等),效果并不理想,后期在采用“基于强化学习的人类反馈学习”技术后发生“蝶变”,迅速成为爆款应用。
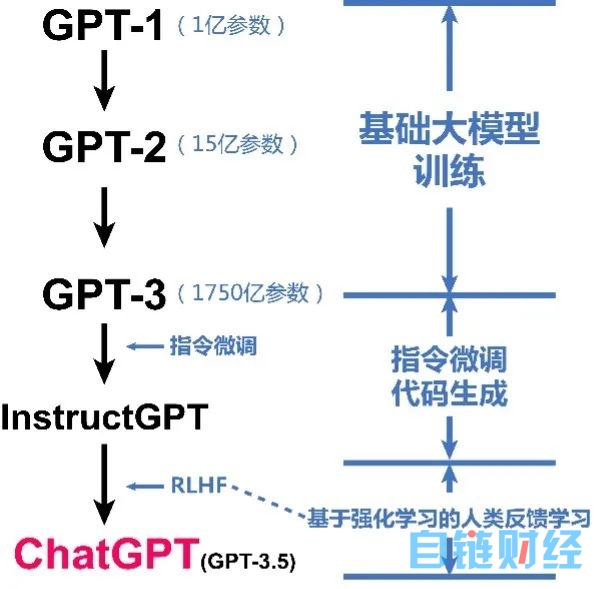
图ChatGPT发展路径
ChatGPT关键在于“三大支撑”。一是“大模型”。全称是“大语言模型”(Large Language Model),指参数量庞大(目前规模达千亿级)、使用大规模语料库进行训练的自然语言处理模型,是ChatGPT的“灵魂”。二是“大数据”。GPT-1使用了约7000本书籍训练语言模型。GPT-2收集了Reddit平台(美国第五大网站,功能类似于国内的百度贴吧)800多万个文档的40GB文本数据。GPT-3使用维基百科等众多资料库的高质量文本数据,数据量达到45TB,是GPT-2的1150倍。三是“大算力”。以GPT-3为例,其参数量达1750亿,采用1万颗英伟达V100 GPU组成的高性能网络集群,单次训练用时14.8天,总算力消耗约为3640PF-days(假如每秒进行一千万亿次计算,需要3640天)。
ChatGPT标志着里程碑式的技术进步。一是在最具挑战性的自然语言处理领域实现了革命性突破。相比视频、图像、语音等,自然语言的语法、语义、逻辑复杂,存在多样性、多义性、歧义性等特点。文本数据稀缺,通常表现为非结构化的低质量数据。自然语言处理任务种类繁多,包括语言翻译、问答系统、文本生成、情感分析等。因此,长期以来自然语言处理被认为是人工智能最具挑战性的领域。ChatGPT不仅实现了高质量的自然语言理解和生成,并且能够进行零样本学习和多语言处理,为自然语言处理领域带来了前所未有的突破。二是标志着通用人工智能的起点。在此之前,人工智能在不同场景应用需要训练不同模型。而ChatGPT利用单一大模型即可完成人机对话、机器翻译、编码测试等多种任务,已经具备通用人工智能的一些核心技术和特征:能够自动化地学习各种知识、信息,不断自我优化;充分理解和流畅表达人类语言,逻辑推理强,实现了具备一般人类智慧的机器智能;拥有一定的自适应和迁移学习能力,可以适用于多种应用场景和任务。三是代表着强人工智能的拐点。ChatGPT证明了大模型的学习和进化能力,将推动强人工智能(机器拥有知觉和意识,有真正的推理和解决问题的能力)加速演进。目前大模型智能程度已接近人类水平,甚至一些业界人士认为,将来会逐渐产生自我认知和感知,进而出现意识并且超越人类。
全球通用人工智能技术加速演进。ChatGPT涉及到“三大”中的“大模型”是核心和独门秘籍。当前,隐藏在ChatGPT背后的“大模型”正越来越多进入人们的视野。国际上已掀起从“大炼模型”到“炼大模型”的技术热潮。OpenAI公司将继续推进ChatGPT的模型演进,目前已发布多模态预训练大模型GPT-4,实现了几个方面跃升:强大的图像识别能力;文字输入上限提升到2.5万字;回答问题准确性明显提高;可以生成创意文本、歌词,实现风格变化等。谷歌创设了1370亿参数级大型自然语言对话模型LaMDA。当前正加快推出基于LaMDA的聊天机器人Bard,并动员全公司开展内测。微软与英伟达合作推出了5300亿参数的MT-NLG模型,与两家公司之前各自的系统相比,优点在于更加擅长各种自然语言任务,例如自动生成句子、问答、阅读和推理、词义消岐等。Meta公司复现了GPT-3,并对所有社区免费开放。
以ChatGPT为代表的人工智能大模型渗透到各行各业,将引发新一轮人工智能革命。从本质上看,ChatGPT是一个“大模型”(参数量巨大的概率模型),其成功实践充分证明了作为通用技术的大模型在人类社会各个方面布局应用的潜力。一是成功探索了大模型的商业模式。ChatGPT已经应用于商用搜索引擎和办公软件,嵌入GPT-3.5的微软必应搜索引擎可以更好理解和响应用户查询,提供更准确的搜索结果,嵌入GPT-4的Office软件大幅提升了办公效率。二是短期来看大模型将替代服务业的一些工作。ChatGPT可以完成各类文本生成任务,替代行政管理人员、科研人员、法律行业人士、媒体从业者、客服人员的部分工作。能够编码、检测安全漏洞,替代软件工程师的一些工作。可以高质量完成语言间的转换,替代翻译人员的部分工作。三是随着大模型不断渗透,人们的生产生活方式将发生深刻变革。在不久的将来,广泛开发应用的大模型将以超出人类的速度和准确性来执行自动化生产、智能制造任务,赋能交通、医疗、金融等各个行业。这将会引发以强人工智能和通用人工智能为代表的新一轮智能革命,大幅提高生产效率,带来经济、社会和产业的深刻变革。
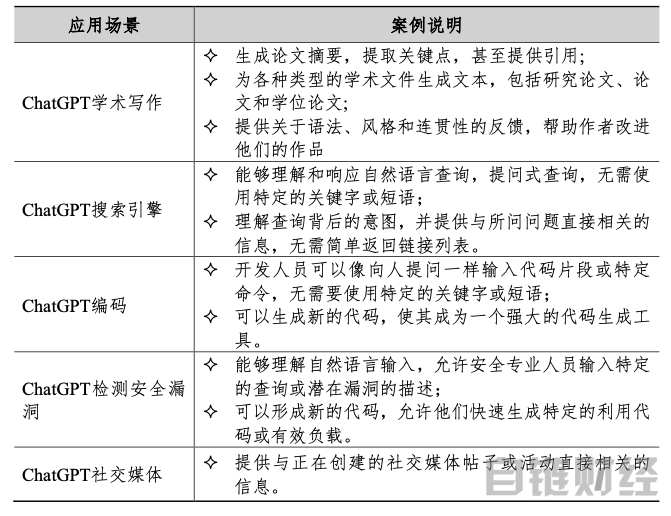
表 ChatGPT主要应用场景
我国人工智能“大模型”现状与面临的问题
国内大模型已具备一定基础,但与ChatGPT还存在一定差距。一是百度自主研发的“文心”大模型,参数规模达2600亿,已在能源、金融、制造等领域发布了11个行业大模型。二是阿里达摩院推出10万亿参数的多模态M6大模型。三是华为与鹏城实验室合作开发的盘古大模型,是首个全开源2000亿参数中文预训练语言模型,在知识问答、知识检索、知识推理、阅读理解等文本生成领域表现突出。四是北京智源人工智能研究院推出1.75万亿参数的悟道2.0,可以同时处理中英文和图片数据。浪潮和中科院也分别推出了相应的大模型等。

从技术能力来看,专家判断当前国内技术比ChatGPT主要差在大模型环节,包括清洗、标注、模型结构设计、训练推理的技术积累。ChatGPT背后是文本/跨模态大模型、多轮对话、强化学习等多技术的融合创新,而国内大部分科技企业、科研院所多聚焦垂直应用,缺乏多技术融合创新能力。从落地应用来看,国内头部企业均表示已开展相关技术研发或部分模型进入内测阶段,但仍未出现与ChatGPT抗衡的大模型产品。加之大模型的训练成本较高,技术应用面临着亿元级研发投入和海量训练试错,国内企业投入严重不足,研发推广和产业落地整体落后于海外。
差距背后存在深层次制约因素,或使中美“大模型”差距进一步拉大,主要表现为三个“缺少”:
缺少高质量训练数据。GPT-3模型训练需要的语料75%是英文,3%是中文,还有一些西班牙文、法文、德文等语料集,这些学习语料可通过公开数据(如维基百科、百度百科、微博、知乎等)、开源数据集、网页爬取(训练GPT-3爬取了31亿个网页,约3000亿词)、私有数据集(如OpenAI的WebText数据集,收集了Reddit平台上的800万篇高赞文章,约150亿词)等方式获取。这些语料中,英文语料公开数据更多、质量更高。中文开源高质量数据少,特别是构建通用领域大模型的百科类、问答类、图书文献、学术论文、报纸杂志等高质量中文内容。同时,国内专业数据服务还处于起步阶段,可用于人工智能模型训练的经过加工、清洗、标注的高质量数据集还相对匮乏。缺少高质量训练数据已成为国内大模型训练的核心痛点。
缺少充足的智能算力支撑。一是大模型训练和运营算力成本高昂。训练阶段,目前业界测算ChatGPT训练成本约为1000万美元,为研发拥有部分ChatGPT能力的大模型,至少需要上千张A100训练卡。运营阶段,ChatGPT云计算成本每日约200万美元。二是缺乏大规模并行计算工程能力。满足大模型训练的算力需求不仅需要数量巨大的高性能GPU,更需要面向人工智能高度优化的云计算平台和相应的工程能力。三是采购国外先进GPU受限,国产算力尚未成熟到支撑大模型研发。国产智能芯片不仅在算力、带宽等性能上同英伟达A100、H100芯片有差距(这两款都在美方对华禁售之列),支持自然语言处理和大模型训练的算子库也不够成熟,国产替代仍有软硬适配等技术问题尚待持续优化与解决。四是人工智能算力市场和服务市场“碎片化”加剧。全国多地主导建设近百个智算中心,形成一个个孤立破碎的人工智能算力和服务小市场,中国大市场优势被消解。
缺少适合大模型研发特点的机制。一是力量分散。人工智能大模型具有长周期、重投入、高风险等特点。国内企业、高校在“大模型”“大数据”“大算力”等方面各有侧重,研发力量分散,资源缺乏整合,没有与OpenAI技术实力对标的企业。二是资金投入不足,企业受盈利压力很难长期维持高投入。政府项目的支持力度与所需投入相比仍显乏力,决策周期长。三是领军人才和核心团队缺乏。ChatGPT团队共87人,绝大多数拥有世界名校学历和知名企业工作经历。而国内人工智能顶级人才分散在不同机构中,很难形成掌握核心技术并且有强大工程能力和项目经验的领军人物和团队。
相关政策建议
人工智能大模型具有重要的战略意义,是未来科技竞争的制高点,也是重要的智能基础设施。需从战略高度重视ChatGPT引发的新一轮人工智能革命,从算法、算力、数据等方面加快布局和突破,构建包容创新的监管环境,积极应对新一轮人工智能科技竞争。
一是瞄准通用人工智能“大模型”发力,加快推动大规模应用。基于通用数据集的大模型是人工智能走向商业化应用落地的重要手段,将带动新的产业和服务应用范式。建议加快自然语言处理、计算机视觉以及多模态大模型攻关。同时,在细分领域构筑优势,进一步深耕垂直领域,从实际场景中积累行业数据和知识,加快孵化人脸识别、音频生产、财务分析、法律服务、教育培训等行业大模型,逐步完善模型架构、提升参数数量,推进应用落地。
二是整合“大数据”,聚焦打造专业数据服务。训练大模型需要优质的大数据集合,有些数据还需要人工标注。收集和清洗数据是一项耗时较长的基础性工作,其质量直接决定模型的智能程度。建议加快推动数据资源整合共享和开发利用。ChatGPT的成功因素之一是拥有大量的优质训练数据。我国具备海量数据和丰富应用场景,建议进一步促进图书、期刊和传统行业的优质数据开放,激发数据要素活力。制定政府公共数据资源开放清单,开展数据资源开放试点,优先开放高价值、低敏感、数据量大的民生公共数据,逐步开放公共数据库、专业数据库等。培育专业数据服务商,培育壮大数据采集、标注、清洗等服务产业。扩大优质数据供给,特别是加快推进历年来中文图书、纸质文献等的数字化,搭建用于人工智能大模型训练的优质数据集,扩大面向人工智能大模型的数据供给。
三是布局“大算力”,聚焦建立算力统一大市场。充分发挥市场机制的作用,坚决遏制低水平、不可持续、缺乏商业闭环的智算中心盲目建设,避免算力市场和人工智能服务市场的碎片化。支持围绕云计算建设的各类行业训练数据集、人工智能训练平台,形成从理论模型创新、模型工程化到场景化服务的技术和商业闭环,构建统一、开放、有序的人工智能产业大生态。建立人工智能计算资源共享名录,支持各省市超算中心、算力平台、行业训练数据集、人工智能训练平台等人工智能基础设施资源开放共享。
四是支持以头部企业为主体,推动形成人工智能“大模型”攻坚合力。加大对头部企业开展大模型核心技术攻关的支持力度,发挥重点企业和研究机构的数据、算力、算法和人才优势,联合产业链上下游企业、高校院所、新型研发机构,协同开展科研攻关,加快推出国产大模型拳头产品。
五是实施包容审慎的监管,为新生事物发展留足空间。类ChatGPT产品作为新生事物,不可能十全十美,鼓励发展是主旋律。ChatGPT初期也会不断“犯错误”,但其自身也逐步建立了技术机制,针对内容、伦理等相关风险进行了过滤与阻断,经过用户反馈、专家机制优化迭代后逐步成熟完善。依托优良的网络环境,丰富的内容治理经验,以及完善的AI监管框架,我国完全具备对于以ChatGPT为代表的人工智能大模型技术治理自信。因此,面对可能出现伦理、数据、舆情等风险,要建立容错机制,实行沙盒监管和敏捷治理,实现规范与发展的动态平衡。